

목차
멀티테넌시란?
멀티 테넌시(Multi-tenancy)는 소프트웨어 애플리케이션의 단일 인스턴스가 여러 고객(테넌트, tenant)에게 서비스를 제공할 수 있게 설계된 아키텍처입니다. 오로지 소프트웨어에 의해서 테넌트가 분리됩니다. 주로 SaaS 클라우드 서비스를 설계할 때 멀티테넌시 아키텍처를 고려합니다. 테넌트를 영어 사전에서 검색해보면 세입자, 임차인이라는 뜻이 검색됩니다. 즉, 우리가 제공하는 서비스를 사용하고 있는 고객의 단위를 테넌트라고 합니다. 예를 들면, B2B 서비스인 경우에는 하나의 고객사를 테넌트라고 부를 수 있습니다.
멀티테넌시를 적용하는 이유
- 고객이 추가될 새로운 시스템을 구축할 필요가 없으므로 신규 고객 추가/삭제에 들어가는 비용이 거의 0에 가깝습니다.
- 무료 체험 등의 서비스를 제공하여 잠재 고객의 접근성을 높일 수 있습니다.
- 모든 테넌시에게 동일한 환경에서 동일한 버전의 서비스를 제공할 수 있게 되어 운영 비용을 줄일 수 있습니다.
주의 사항
애플리케이션의 버그로 인해 테넌트 상호 간의 정보가 노출되지 않도록 주의해야 합니다.
멀티테넌시 아키텍처 적용 방안
하나의 물리적인 서버에서 단일 애플리케이션이 데이터를 테넌트 별로 분리하여 관리하기 위한 4가지 방법에 대해서 알아보겠습니다. 언제나 옳은 정답이 있는 것은 아니므로 테넌트의 데이터 격리 수준과 그에 따른 구현 난이도, 처리 속도 등을 고려하여 상황에 따라 적절한 방법을 선택할 수 있으며, 필요에 따라 하이브리드 방식을 취할 수도 있습니다.
- 운영 비용 : 레코드 == 테이블 == 스키마 < DBMS 서비스
- 데이터 격리 수준 : 레코드 < 테이블 < 스키마 < DBMS 서비스
- 구현 난이도 : 레코드 < 테이블 < 스키마 == DBMS 서비스
레코드 수준의 데이터 분리
모든 테넌트가 하나의 DBMS 서비스를 공유하면서 레코드 수준으로 테넌트의 데이터를 분리하여 관리하는 방법입니다. 예를 들면, 각 테넌트의 레코드를 식별하기 위해서 테넌트 ID를 저장하는 컬럼을 만들 수 있습니다.
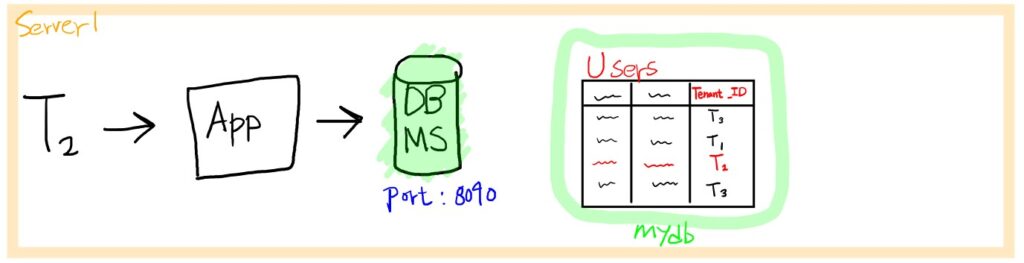
위 그림처럼 테넌트 T2가 users 테이블을 조회할 때 T2에 해당하는 정보만 조회하기 위해서, 하나의 DBMS 서비스에서 mydb 데이터베이스의 Users 테이블의 Tenant_ID 컬럼 값이 T2인 데이터를 조회하는 방법을 고려해볼 수 있습니다. 모든 테넌트의 데이터가 하나의 테이블 안에 저장됩니다.
장점
- 구현하기 쉽습니다.
- 컬럼의 값으로 테넌트를 식별하므로 테넌트 추가시 별도의 작업이 필요하지 않습니다.
단점
- 모든 테넌트의 데이터가 하나의 테이블에 섞여있어 관리하기 어렵습니다.
- 겉으로 보았을 때 어떤 테넌트가 있는지 알 수 없습니다.
- 멀티테넌시 아키텍처에 의존하는 비즈니스 로직을 작성하게 됩니다.
- 특정 테넌트가 삭제될 경우 모든 테이블에서 해당 테넌트의 정보를 삭제해야 합니다.
테이블 수준의 데이터 분리
모든 테넌트가 하나의 DBMS 서비스를 공유하면서 테이블 수준으로 테넌트의 데이터를 분리하여 관리하는 방법입니다. 예를 들면, 테넌트가 추가될 때 해당 테넌트를 위한 테이블을 하나씩 생성할 수 있습니다.
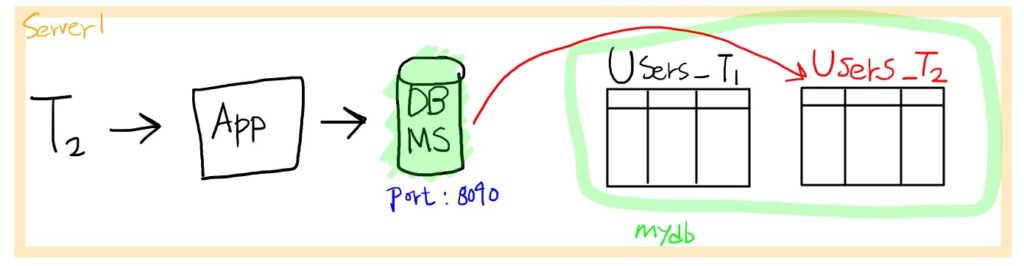
위 그림처럼 테넌트 T2가 users 테이블을 조회할 때 T2에 해당하는 정보만 조회하기 위해서, 하나의 DBMS 서비스에서 mydb 데이터베이스의 Users_T2 테이블을 조회하는 방법을 고려해볼 수 있습니다. n개의 테넌트가 추가되면 n개의 Users 테이블이 생성되어야 합니다. (Users_T1, … ,Users_Tn)
장점
- 구현하기 쉽습니다.
- 테이블만 보고 어떤 테넌트의 데이터인지 알 수 있습니다.
단점
- 모든 테넌트의 테이블들이 섞여있어 관리하기 어렵습니다.
- 멀티테넌시 아키텍처에 의존하는 비즈니스 로직을 작성하게 됩니다.
- 테넌트 추가/제거 시 해당 테넌트를 위한 테이블들을 추가/제거하는 작업이 필요합니다.
스키마 수준의 데이터 분리
모든 테넌트가 하나의 DBMS 서비스를 공유하면서 스키마 수준으로 테넌트의 데이터를 분리하여 관리하는 방법입니다. 예를 들면, 테넌트가 추가될 때 해당 테넌트를 위한 논리적인 DB를 하나씩 생성할 수 있습니다.
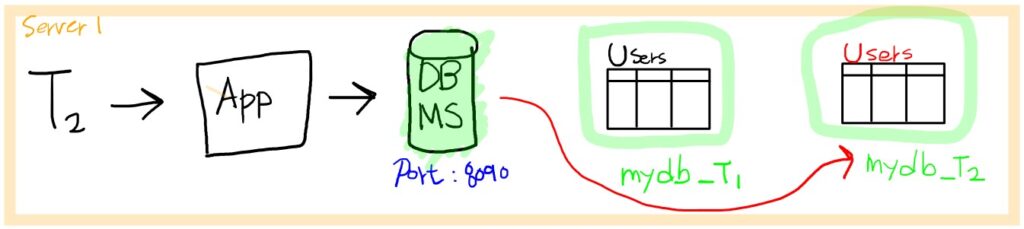
위 그림처럼 테넌트 T2가 users 테이블을 조회할 때 T2에 해당하는 정보만 조회하기 위해서, 하나의 DBMS 서비스에서 논리적으로 분리되어 있는 mydb_T2 데이터베이스의 Users 테이블을 조회하는 방법을 고려해볼 수 있습니다. n개의 테넌트가 추가되면 n개의 데이터베이스가 생성되어야 합니다. (mydb_T1, … ,mydb_Tn)
장점
- 어떤 테넌트의 데이터인지 파악하기 쉬운 편입니다.
- 테넌트에 따라서 다른 데이터베이스 커넥션을 사용하도록 구현되므로 비즈니스 로직은 멀티테넌시 아키텍처에 의존하지 않습니다.
단점
- 구현하기 어려울 수 있습니다.
- 테넌트 추가/제거 시 해당 테넌트를 위한 데이터베이스를 추가/제거하는 작업이 필요합니다.
DBMS 서비스 수준의 데이터 분리
테넌트마다 다른 port 번호를 가진 DBMS 서비스를 할당하여 데이터를 분리해서 관리하는 방법입니다. 예를 들면, 테넌트가 추가될 때 해당 테넌트를 위한 DBMS 서비스를 하나씩 실행시킬 수 있습니다.
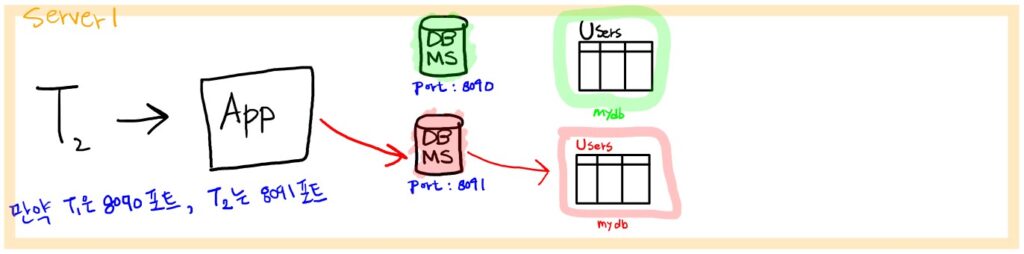
위 그림처럼 테넌트 T2가 users 테이블을 조회할 때 T2에 해당하는 정보만 조회하기 위해서, 8091 포트에 할당된 DBMS 서비스의 mydb 데이터베이스의 Users 테이블을 조회하는 방법을 고려해볼 수 있습니다. n개의 테넌트가 추가되면 n개의 DBMS 서비스가 각각 다른 포트를 사용하여 실행되어야 합니다.
장점
- 데이터를 확실하게 분리해서 관리할 수 있습니다.
- DBMS 서비스가 더 많은 트래픽을 감당할 수 있습니다.
단점
- 서버가 비교적 많은 리소스를 필요로 합니다.
- 안정적으로 유지해야 하는 DBMS 서비스가 많아집니다.
- 테넌트 추가/삭제 시 비교적 많은 비용이 발생합니다.
참고 자료
- 멀티테넌트 클라우드를 사용해야 하는 이유
https://www.itworld.co.kr/t/62082/it%20%EA%B4%80%EB%A6%AC/216079 - 다중 테넌트 솔루션에 대해 고려해야 하는 테넌트 모델
https://learn.microsoft.com/ko-kr/azure/architecture/guide/multitenant/considerations/tenancy-models



좋은 글 작성해주셔서 감사합니다. 잘 읽었습니다.
중간 내용 중 테이블들이 섞여 있어 관리하기 어렵다는 부분에서, 만약 테이블이 분리되어 있을 경우에 테이블의 구조가 변경되거나 마이그레이션이 필요할 경우에는 오히려 관리가 용이할 것 같은데, 장점이자 단점으로 볼 수 있을까요?