

목차
HashMap은 Key, Value의 쌍으로 데이터를 관리할 수 있는 자료 구조이다. 순서를 보장하지 않으며, Key의 중복을 허용하지 않는다. HashMap의 Hash는 자료를 조회하는 방법과 관련이 있고 Map은 자료의 특성과 관련이 있다. 자바(java)에서 자주 사용되는 Collection 중 하나다. 필자는 객체가 이미 존재하는 경우에 해당 객체의 특정 필드 값만 취하기 위해서 HashMap의 containsKey를 사용한 적이 있다. 그 과정에서 알게 된 내용들을 공유하고자 한다.
제대로 알고 활용하려면 Hash라는 개념에 대해 아는 것이 중요하다. 그래야 이해가 쉽다. 먼저 Hash에 대한 설명을 하고 Hash에 대한 이해를 바탕으로 해시맵을 어떻게 활용할 수 있는 지 살펴보는 순서로 글을 작성했다.
Hash란?
Hash는 자료를 일정한 형식의 식별 값으로 나타내기 위한 노력의 산물이다. 왜 굳이 그런 노력을 해야 했던 걸까? 100,000개의 자료가 저장된 리스트가 있다고 해보자. 100,000개의 자료 중에서 내가 원하는 자료를 찾고자 할 때 가장 먼저 떠올릴 수 있는 방법은 100,000개의 자료를 처음부터 끝까지 순회하면서 하나씩 비교하여 우리가 찾는 자료가 맞는지 확인하는 것이다. 우리가 찾는 자료가 없다는 사실을 알기 위해서는 처음부터 끝까지 모두 확인해야만 확실하게 알 수 있다. 자료의 개수가 늘어나서 10억 개가 되면 매번 10억 개의 자료를 다 훑어봐야 한다. 더 좋은 방법이 있어야 할 것 같지 않은가? Hash는 10억 개의 자료 중에서도 우리가 원하는 자료를 빠르게 찾아낼 수 있도록 돕는다.
Hash의 활용
여기 특정 문자열을 식별 가능한 정수로 변환해주는 Hash Function이 있다. 이 Hash Function의 input이 “타깃 코더” 라면 output은 반드시 일관된 정수 값이 되어야 한다. input 값이 동일한데 output이 다른 케이스가 있으면 Hash Function이라고 할 수 없다. 아래 그림의 Hash Function은 “타깃 코더”가 들어오면 반드시 10041004만 뱉는다. 이렇게 입력을 해시 값으로 변환하는 과정을 통틀어 해싱이라고 한다.
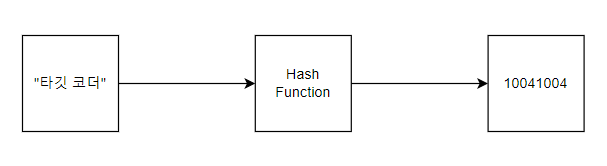
문자열을 정수로 매핑하는 것이 가능해지면 10억 개의 자료 중에서 내가 원하는 자료를 찾기 위해 10억 개의 자료를 모두 훑어 볼 필요가 없다. 단 한 번에 찾을 수 있다. 어떻게 그럴 수 있을까? 아래의 그림과 같이 문자열과 매핑된 정수를 배열의 인덱스로 사용하면 된다. 이렇게 하려면 할당된 배열의 최대 크기를 넘지 않도록 Hash 값의 길이를 조절해줘야 한다. 해싱에 대해 더 깊게 공부하고 싶다면 Hash Table에 대해서도 검색해보라.
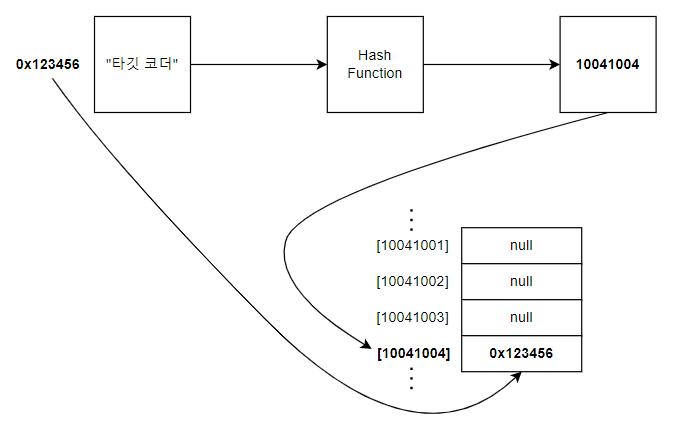
해시 충돌
그런데 문제가 있다. 문제는 Hash Function은 완벽할 수 없다는 것이다. 아무리 공들여 해시 함수를 만들어도 입력 데이터의 수가 많아지면 문제가 생길 수 있다. 서로 다른 입력에 대한 해시값을 동일하게 생성해버릴 확률이 존재한다. 그래서 Hash 값이 충돌하는 경우까지 대비하여 알고리즘을 설계해야 한다. 다행히 우리가 그것까지 구현할 필요는 없다. 이미 해시맵 내부적으로 그렇게 구현되어 있으니 걱정하지 말고 주어진 기능을 사용하면 된다. 하지만 내부적으로 어떻게 동작하는 지 이해하고 있으면 문제가 발생하거나 응용이 필요한 상황에서 좀 더 수월하게 일을 해결할 수 있을 것이다.
메모리 사용량과 해시 충돌의 관계
메모리 사용량과 해시 충돌의 관계도 알아두면 좋다. 해시값의 범위가 넓을 수록 충돌 확률은 줄어들지만 메모리 사용량은 늘어나고, 해시값의 범위가 좁을 수록 충돌 확률이 높아지고 메모리 사용량은 줄어든다. 조금만 생각해보면 당연한 이야기다. 해시값의 범위가 0~10 인데 정수로 나타내야 하는 문자열은 20개가 있다면 충돌이 발생할 수 밖에 없지만, 해시의 범위가 0~1000인데, 정수로 변환될 문자열은 20개 뿐이라면 충돌이 일어날 확률은 작아진다.
자, Hash에 대한 기본적인 개념 설명은 이쯤 하면 된 것 같으니 HashMap 활용 방법을 알아보자.
HashMap 이해하기
여러 개의 필드를 가진 인스턴스를 Key로 하여 특정 Value를 매핑해서 관리해야 한다면 자바에서 제공하는 Collection 중에 어떤 것을 사용해야 할까? Key는 중복되지 않아야 하고, 자료가 많아도 빠른 조회가 가능해야 한다면? 이런 경우에 HashMap을 활용해서 문제를 해결할 수 있다.
해시맵은 <Key, Value> 쌍으로 자료를 관리하며 Key로 주어진 객체를 해싱해서 Key에 매핑된 Value를 빠르게 조회할 수 있게 한다. 우리는 Object로 부터 상속 받는 두 가지 메서드(method)를 알아야 한다. 하나는 ①int hashCode()이다. hashCode 메서드는 그림 1-1에 있는 Hash Function의 일종이다. 우리는 hashCode 메서드를 오버라이딩(overriding)해서 해싱 알고리즘을 직접 구현할 수 있다. hashCode 메서드가 반환하는 해시값을 사용하면 그 값에 매핑 되어있는 인스턴스들에게 한 번 만에 접근할 수 있게 된다.
앞에서 Hash Function은 완벽하지 않아서 다른 두 문자열의 hash가 충돌할 수도 있다는 이야기를 했었다. hashCode 메서드를 통해 생성되는 Hash 값이 같은 인스턴스가 여러 개 있다면 동일한 Hash에 여러 개의 인스턴스가 매핑된다. 이 때 여러 개의 인스턴스 중에 우리가 찾는 인스턴스를 찾아내기 위해서 두 인스턴스를 비교하는 또 다른 method가 사용된다. 그 메서드는 바로 ②boolean equals(Object)이다. 따라서 우리는 해시맵을 원하는 대로 사용하기 위해 이 두 메서드를 overriding 해야 한다.
HasIhMap 사용 방법
import java.util.HashMap;
HashMap<Student, String> studentMap = new HashMap<Student, String>();
studentMap.put(new Student(), "string");가장 기본적인 인스턴스 생성, 자료 추가에 대한 코드만 작성해보았다. 먼저 java.util.HashMap 클래스를 import 해야 한다. 인스턴스를 생성할 때는 HashMap<Key 객체의 클래스명, Value 객체의 클래스명> 형태가 된다. 위 코드는 생성자에 인자를 넘겨주지 않았지만 List를 인자로 넣어 인스턴스 생성 시점에 자료를 추가할 수도 있다. 생성된 HashMap에 자료를 추가할 때는 put 메서드를 사용하고 어떤 Key의 존재 여부를 확인할 때는 containsKey 메서드를 사용한다. 그 외 제공되는 다양한 기능의 인터페이스를 여기(👈 click!!) 에서 확인할 수 있다.
예시 클래스 및 테스트 코드
백문이 불여일견. 어떤 식으로 Entity를 만들 수 있는 지 예시를 살펴보고, 작성된 클래스의 객체가 Key로 사용되는 경우에 어떻게 동작하는 지 테스트 코드를 통해 알아보자. 실제로 이렇게 하는 경우는 거의 없겠지만 이해를 돕기 위해 Student 엔티티는 id와 age 두 개의 필드로 동일성을 따진다고 가정한다. 즉, Student 객체는 id, name 값이 동일하면 age가 다르더라도 같은 객체로 판단되어야 한다.
Student.Class
public class Student {
private String id;
private String name;
private int age;
public Student(String id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public String getId() {
return this.id;
}
public String getName() {
return this.name;
}
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) {
return false;
}
Student anotherStudent = (Student)o;
return id.equals(anotherStudent.getId()) && name.equals(anotherStudent.getName());
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}해시 충돌이 발생하거나 단순히 두 Student 객체를 equals 메서드로 비교할 때는 두 객체의 id, name이 동일하면 같은 객체라고 판단할 수 있도록 equals 메서드를 오버라이딩 했다. 비교 대상 객체가 null이거나 클래스가 동일하지 않으면 무조건 false를 반환한다.
hashCode 메서드는 Objects.hash 메서드를 사용해 hashCode를 생성하도록 오버라이딩 했다. 인자 값으로 age를 제외하고 id, name 만을 넘겨주었기 때문에 Student 객체의 해시값은 id, name 두 개의 필드만 사용해서 생성된다.
StudentTest.class
public class StudentTest {
public static final String TEST_ID_1 = "targetcoders1";
public static final String TEST_ID_2 = "targetcoders2";
public static final String TEST_ID_3 = "targetcoders3";
public static final String TEST_NAME_1 = "taco1";
public static final String TEST_NAME_2 = "taco2";
public static final String TEST_NAME_3 = "taco3";
public static final int TEST_AGE_1 = 50;
public static final int TEST_AGE_2 = 60;
public static final int TEST_AGE_3 = 70;
@Test
public void testEqualsTrue() {
Student studentOne1 = new Student(TEST_ID_1, TEST_NAME_1, TEST_AGE_1);
Student studentOne2 = new Student(TEST_ID_1, TEST_NAME_1, 100);
Assert.assertEquals(studentOne1, studentOne2);
}
@Test
public void testEqualsFalse() {
Student studentOne = new Student(TEST_ID_1, TEST_NAME_1, TEST_AGE_1);
Student studentTwo = new Student(TEST_ID_2, TEST_NAME_1, TEST_AGE_1);
Assert.assertNotEquals(studentOne, studentTwo);
}
@Test
public void testContainsTrue() {
Map<Student,String> studentHashMap = createDefaultStudentHashMap();
Student target = new Student(TEST_ID_1, TEST_NAME_1, TEST_AGE_1);
Assert.assertTrue(studentHashMap.containsKey(target));
}
@Test
public void testContainsFalse() {
Map<Student,String> studentHashMap = createDefaultStudentHashMap();
Student target = new Student(TEST_ID_2, "testName", TEST_AGE_2);
Assert.assertFalse(studentHashMap.containsKey(target));
}
@Test
public void testGetTargetStudentId() {
Map<Student,String> studentHashMap = createDefaultStudentHashMap();
Student target = new Student(TEST_ID_2, TEST_NAME_2, TEST_AGE_1-1);
Assert.assertEquals(TEST_ID_2, studentHashMap.get(target));
}
private Map<Student, String> createDefaultStudentHashMap() {
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(TEST_ID_1, TEST_NAME_1, TEST_AGE_1));
studentList.add(new Student(TEST_ID_2, TEST_NAME_2, TEST_AGE_2));
studentList.add(new Student(TEST_ID_3, TEST_NAME_3, TEST_AGE_3));
HashMap<Student, String> studentHashMap = new HashMap<>();
for (Student student : studentList) {
studentHashMap.put(student, student.getId());
}
return studentHashMap;
}
}아래의 세 가지를 테스트하는 코드이다. 천천히 읽어보면서 동작 방식을 이해해보길 바란다.
- 두 엔티티를 비교하는 equals 메서드 테스트
- 저장된 Key가 이미 존재하는지 확인하는 containsKey 메서드 테스트
- 저장된 Key와 매핑되는 Value를 잘 가져오는지 확인하는 테스트


